
We're the team behind PromptMetrics. That makes us biased.
But here's the reality: we built PromptMetrics because we were frustrated AI founders ourselves, staring at agent failures we couldn't explain and compliance deadlines we couldn't ignore. Instead of pretending this is an "independent analysis," we're giving you our assessment of the auditability gap in current agent frameworks, where PromptMetrics fits, and—crucially—where it doesn't.
If you decide to walk away because you don't need audit-grade observability yet, that's valid. We'd rather earn your trust now than sell you something that won't help when the auditor actually shows up.
What We're Reviewing
The collision between autonomous AI agents and EU AI Act auditability requirements. Specifically, why frameworks like LangChain, LangGraph, and CrewAI fail the "auditability test," and what it takes to be ready by August 2026.
The core problem is simple: An auditor asks why your AI agent recommended Treatment A over Treatment B. You have 30 seconds to answer. Can you?
If you're running multi-step AI agents in healthcare, finance, or legal services, the answer is likely no. Most EU AI Act agent framework options were built for functionality—chaining tool calls and optimizing throughput. They were not built to explain why a decision was made.
The Stakes: Non-compliance with high-risk AI requirements carries penalties up to €15 million or 3% of global turnover—whichever is higher.
The Pros: What Proper Auditability Does Well
1. It Turns "Why Did That Happen?" Into a Legally Defensible Answer
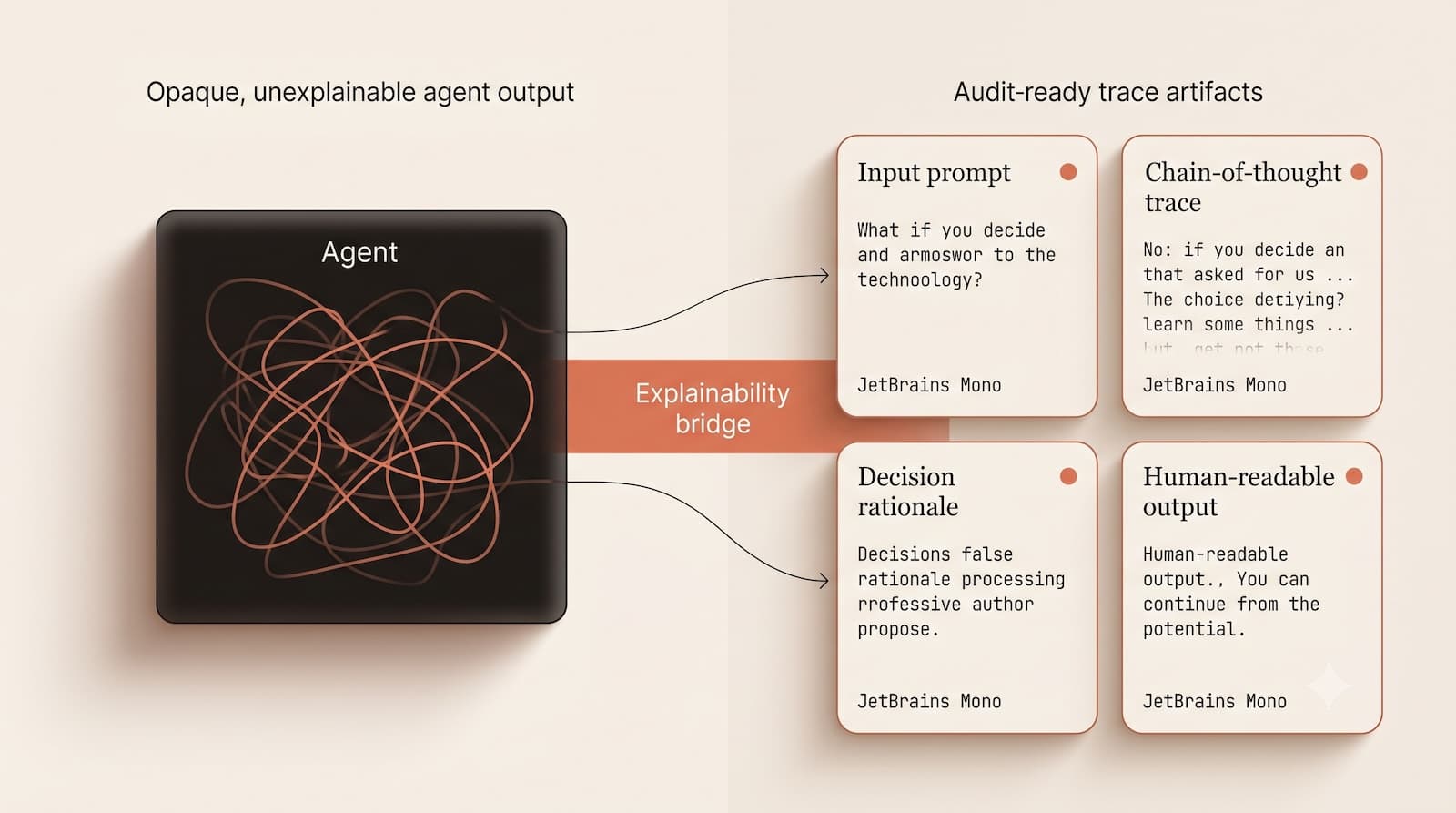
The number one pain point for CTOs isn't just that agents fail; it's that debugging them is a black box. A prompt that worked last week now produces garbage. Without a proper LLM audit trail, you're exposed when the auditor asks for evidence.
Consider the Air Canada case. When its chatbot provided information that contradicted the airline's bereavement fare policy, the company was held liable. The real damage wasn't the $812 CAD payout—it was the precedent that companies are liable for their AI's outputs. Observability makes failures visible. Auditability makes the chain of events explainable and defensible.
2. It Aligns You with Article 12 (and Future-Proofs for RAG)
Article 12 of the EU AI Act mandates that high-risk AI systems "shall technically allow for the automatic recording of events (logs) over the lifetime of the system."
While Article 12(3) specifically mandates logging "reference databases" for biometric systems, it signals the granularity regulators expect. Auditors are increasingly applying the same expectations to RAG-based systems in essential services: logging not just the query but also the exact version of the vector store index and the specific chunks retrieved.
3. It Satisfies Article 86: The Right to Explanation
Here's the one most teams miss: Any person subject to a decision that produces legal effects or similarly significantly affects them—when that decision is based on a high-risk AI system—has the right to obtain "clear and meaningful explanations of the role of the AI system in the decision-making procedure."
If a patient asks why your AI recommended a specific care plan, you are legally obligated to explain it. Traditional observability tools capture inputs and outputs, but they rarely capture the intermediate reasoning required to explain the "why."
4. Human Oversight Becomes Actually Provable
Article 14 requires proving that a human "correctly interpreted the high-risk AI system's output" and took documented action.
Regulators are moving toward a standard of tamper-evident intervention records. It is not enough to have a human-in-the-loop; you need a digital paper trail that proves a specific, credentialed human reviewed the output, stamped it with approval, or executed an override.
The Cons: Where Current Solutions Fall Short
1. Agent Frameworks Weren't Built for Auditors
LangChain, LangGraph, and CrewAI are incredible feats of engineering. But they were architected for builders, not auditors.
As of early 2026, neither LangChain, LangGraph, nor CrewAI's open-source versions include built-in audit logging, authentication, or compliance features in their core frameworks. Developers consistently report that abstraction layers obscure the model's actual decision path, making it difficult to trace individual decisions for legal review.
2. The "Observability vs. Auditability" Trap
There is a critical data gap confusing the market.
According to LangChain's recent State of Agent Engineering reports, 89% of organizations have implemented some form of agent observability. However, Grafana's 2025 survey notes that only 7% have implemented dedicated, production-grade LLM observability.
The discrepancy? Most teams have "debugging" observability (latency, error rates, token counts). They lack "audit" observability (immutable chains of custody, decision lineage, and tamper-proof logs).
Observability tells you the agent failed.
Auditability proves why it failed and what data led to that failure.
3. The "Hallucination" Risk is Higher Than You Think
If you are building in the legal or regulatory space, the risk of unexplainable errors is massive.
A study published in the Journal of Legal Analysis found that LLMs can hallucinate between 58% and 88% of the time when asked specific, verifiable questions about federal court cases. If your agent is operating in a high-stakes environment without an audit trail, a single hallucination could become a compliance nightmare.
4. PromptMetrics Doesn't Replace Legal Counsel
We generate compliance artifacts and map traces to EU AI Act requirements. But we are a software company, not a law firm.
We help you collect and organize the evidence. We do not tell you if your application falls under Annex III (High-Risk). You still need legal counsel to determine your classification. Our tools make the audit faster, but they don't replace human judgment.
Who Should Care About This?
✅ Best For:
Seed to Series A AI startups in High-Risk Annex III categories (e.g., credit scoring, healthcare eligibility, legal interpretation).
Companies with €5K–€30K monthly LLM spend and growing agentic complexity.
Teams using LangChain/LangGraph who need compliance without rebuilding their stack.
Founders are facing investor questions about AI governance.
❌ Not Right For:
< 1,000 LLM requests/day—basic logging is likely sufficient for now.
Simple, single-model applications (non-agentic).
Teams purely outside EU jurisdiction with no high-risk use cases.
Enterprise organizations need custom, on-premises compliance frameworks (requiring dedicated enterprise tooling).
The Engineering Checklist: What "Audit-Ready" Actually Looks Like
Based on EU AI Act requirements and emerging best practices for forensic reproducibility:
For Every LLM Call
[ ] Model ID and specific version (e.g.,
gpt-4-0613not justgpt-4)[ ] Full system instructions and user prompt
[ ] Temperature and hyperparameter settings
[ ] Complete raw response
For RAG & Tool Calls (Best Practice)
[ ] Specific Vector Store Index ID (to prove what knowledge was available)
[ ] Exact chunks/context retrieved
[ ] The full payload sent to external APIs
For Human Oversight (Article 14 Alignment)
[ ] Identity of the human reviewer
[ ] Timestamp of the review
[ ] Specific action taken (Approved, Rejected, Edited)
[ ] Advanced: Cryptographic signing of review events (provides tamper evidence for litigation scenarios)
Final Verdict
The EU AI Act deadline is August 2026. If you are shipping AI agents in healthcare, finance, or legal sectors today, the time to build auditability is now.
Current agent frameworks are excellent at functionality but inadequate for compliance. The gap between "we have logs" and "we can satisfy an auditor" is where most teams are exposed.
You don't need to rebuild your stack. You need to instrument it properly.
PromptMetrics provides that layer. We're honest about what we do well (compliance artifact generation, immutable tracing, EU-hosted infrastructure) and where we fall short (we aren't lawyers).
If that fits your situation, we'd love to help.
Ready to see if your current stack is audit-ready? Try PromptMetrics free and get your first compliance trace in under 30 minutes: https://app.promptmetrics.dev/register