
TL;DR: The Executive Summary
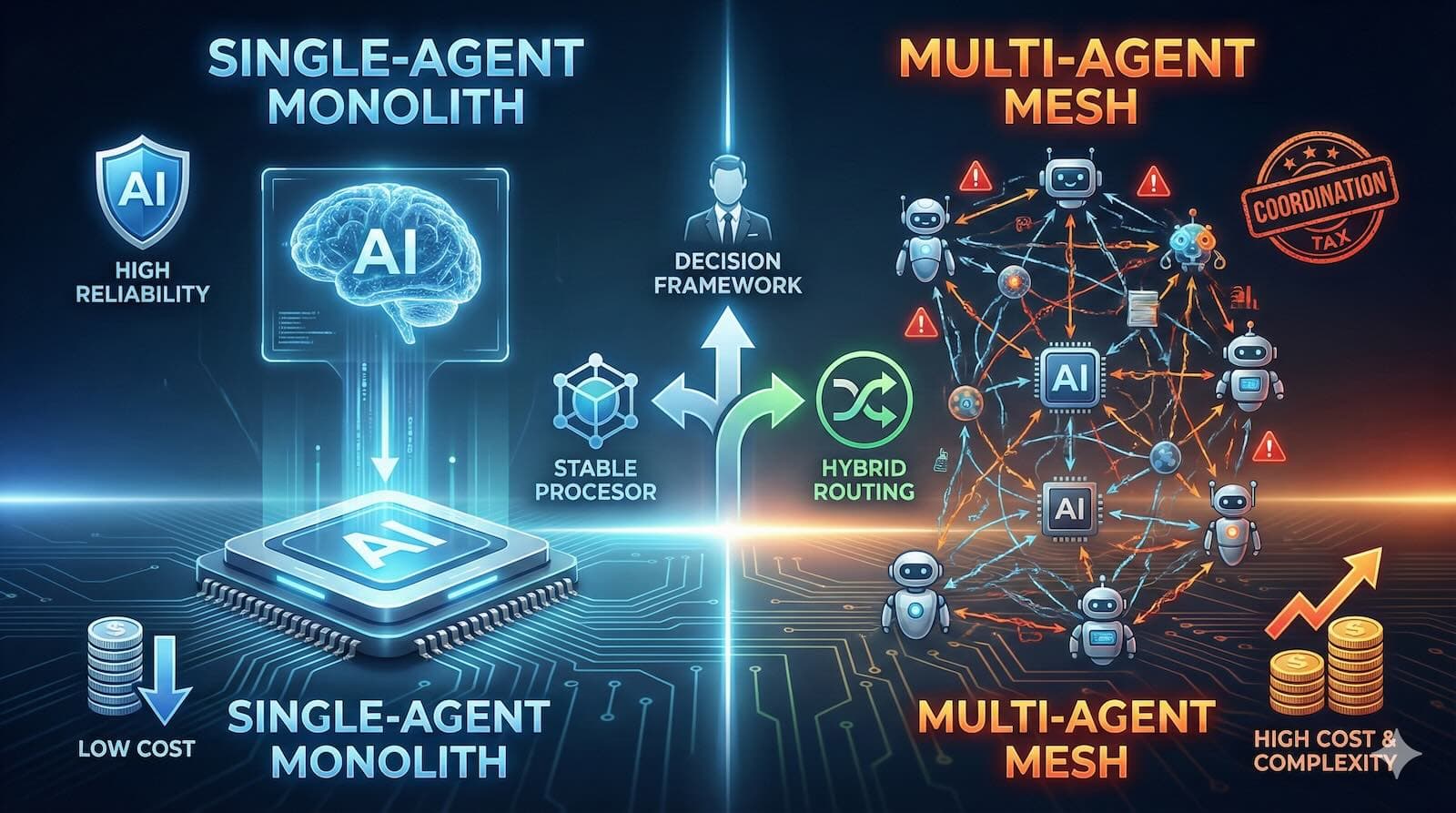
The Trap: Many engineering teams are over-engineering AI pilots into complex "Multi-Agent Systems" (MAS), resulting in a "Coordination Tax" that spikes costs (5x-15x) and complicates debugging without improving accuracy.
The Reality: Empirical data show that for most enterprise tasks (coding, support, data analysis), a Single-Agent System (SAS) with a reasoning model (like o1/o3) outperforms a swarm in terms of accuracy and reliability.
The Rule: Default to Single-Agent First. Only escalate to a Multi-Agent architecture if you trigger specific "Fission Protocols":
Context: The data is too large to fit into a single window.
Security: You need "air-gapped" privilege levels between steps.
Parallelism: You need to execute 50+ independent tasks simultaneously.
The Solution: If you must use MAS, use Hybrid Routing to send simple queries to single agents and only complex tasks to swarms, reducing costs by up to 88%.The promise of "Agentic AI" is seductive. We've all seen the demos: a "society of minds" where autonomous agents, researchers, coders, and critics collaborate seamlessly to build software or solve complex problems while you sleep. It sounds like the ultimate leverage for your engineering team.
But if you are currently staring at a pilot project that is burning tokens at an alarming rate, hallucinating in loops, or simply timing out, you know the reality is different.
You aren't alone. Empirical data shows that multi-agent systems (MAS) often introduce a "Coordination Tax," a hidden cost in reliability, latency, and observability that can cripple production environments. In fact, recent studies of seven state-of-the-art frameworks show failure rates ranging from 41% to 86.7% on complex reasoning benchmarks like software engineering and math problem-solving.
As a technical leader, you are now facing a critical architectural decision: do you build a sophisticated Multi-Agent Mesh or optimize a Single-Agent Monolith?
This isn't just a coding preference; it's a P&L decision. It impacts your cloud costs, your debugging time, and your time-to-market.
This guide strips away the hype to compare these two architectures side-by-side, providing a rigorous framework for when to stick with simplicity, when to embrace the swarm, and how to bridge the gap with hybrid models.
At a Glance: Monolith vs. Mesh
Before we dive into the engineering weeds, let's look at the trade-offs. The industry is currently suffering from "Agentic Inflation," the belief that adding more agents equals more intelligence. Often, the opposite is true.
Here is how the two approaches stack up in production environments:
Feature / Factor | Single-Agent System (SAS) | Multi-Agent System (MAS) | The Reliability View |
Reliability | High (Deterministic execution) | Low to Medium (Emergent failures) | Single agents fail linearly; teams fail geometrically. |
Cost (Tokens) | Base Cost (1x) | 5x - 15x Multiplier | MAS incurs high costs due to redundant context passing and iterative coordination. |
Debuggability | Linear Trace (One stream) | Blame Diffusion (Distributed traces) | Automated root cause attribution in MAS is currently <15% accurate. |
Latency | Sequential (2-40s) | Variable (Potential for parallelism) | MAS is only faster if the task is genuinely parallelizable. |
Context | Unified (Full history access) | Fragmented (Partial views) | SAS wins on deep reasoning; MAS wins on breadth. |
Ideal Use Case | Deep reasoning, sequential tasks, SQL generation. | Broad research, security isolation, and independent sub-tasks. |

The Single-Agent System (SAS): The "Reasoning Monolith"
In a Single-Agent architecture, intelligence is centralized. You have one reasoning loop (often a ReAct or OODA pattern) that maintains a continuous stream of consciousness. It observes, reasons, acts, and observes again.
Why it works
The SAS's superpower is Reasoning Density. Because the agent maintains a unified context window, it has perfect knowledge of its own history. The "Planner" part of the model knows exactly what the "Executor" part just saw, because they are the same entity. There is no game of "telephone" where context is lost between hops.
The Real-World Proof: Alation
Consider the case of Alation. They initially built a complex, hierarchical Multi-Agent system for a Text-to-SQL task (translating natural language into database queries). It made sense on paper: one agent to plan, one to write SQL, one to review.
But in production, it failed. Context fragmentation meant the "Worker" agent didn't fully grasp the nuances of the schema that the "Manager" agent had identified.
They reverted to a Single-Agent architecture using a high-capacity reasoning model (such as OpenAI's o1 or o3).
Accuracy: jumped from 59.87% (MAS) to 77.63% (SAS).
The Trade-off: The single agent actually used 3.2x more tokens (1259 vs 393) because reasoning models "think" more intensely.
The Lesson: Simplicity isn't always cheaper per query, but it is often more effective. High-compute single agents usually beat low-compute swarms in terms of accuracy.
When to choose Single-Agent
Deep Reasoning Chains: If Task B strictly relies on the nuanced output of Task A (e.g., coding, legal analysis).
Unified Context: When the model needs to "hold the whole problem in its head" to solve it.
Debugging Velocity: When you need your engineering team to solve bugs in minutes, not days.
The Multi-Agent System (MAS): The "Orchestrated Mesh"
A Multi-Agent System distributes reasoning across specialized nodes. You might have a "Researcher" who can only search the web, a "Coder" who can only run Python, and a "Manager" who routes traffic.
The Hidden Risks: The "Unreliability Tax"
While MAS offers modularity, it introduces failure modes that do not exist in single-agent systems.
Coordination Deadlock: Agent A waits for Agent B, who is waiting for Agent A. The system hangs, burning money until it times out.
Infinite Loops: An "Actor" and a "Critic" agent get stuck in a loop of rejection and revision that never converges.
Blame Diffusion: When the system fails, who is at fault? The planner? The tool user? The summarizer? Automated root-cause attribution accuracy in these systems is currently below 15%, making manual debugging 3-5x harder than in single-agent systems.
The Real-World Proof: Anthropic
So, when does MAS win? Parallelism.
Anthropic's research highlights the power of sub-agents for broad, open-ended tasks. For strictly serial tasks, agents offer little benefit. However, for "embarrassingly parallel" tasks like broad market research or checking multiple independent news sources, MAS shines.
By spawning 3-5 sub-agents to perform parallel tool usage, they achieved up to a 90% reduction in task completion time compared to a single agent working sequentially.
Key Insight: The win here wasn't "better reasoning"; it was raw throughput.
The Strategic Decision Framework: The "Fission Protocols"
As a CTO, your default posture should be Single-Agent First.
You should only break that monolith a process we call "Architectural Fission" when you trigger specific, evidence-based thresholds. Do not optimize for "cool"; optimize for reliability.
1. The Context Fission Threshold
Split if: The data required exceeds the context window, or if seeing Dataset A would hallucinate results for Dataset B.
Example: A "Prosecutor" agent and a "Defense Attorney" agent. If one agent tries to simulate both, the cognitive dissonance leads to a lukewarm output. You need two separate context windows to enforce distinct worldviews.
2. The Privilege Threshold
Split if: Different steps require different security clearances.
Example: An "Intern" agent interacts with the public (high risk of prompt injection). It passes structured data to a "Manager" agent (isolated), which is the only one allowed to write to the production database.
Why: This implements least-privilege access control, a critical practice recommended by NIST's AI Risk Management Framework for production AI systems.
3. The Parallelism Threshold
Split if: The task can be decomposed into independent sub-tasks that can be run concurrently.
Example: "Check compliance for these 100 contracts." This is not a conversation; it is a batch job. Run 100 agents in parallel.
4. The Capability Saturation Threshold
Split if: Your single-agent benchmarks have plateaued below 45% accuracy.
Research indicates that if a single agent achieves>45% accuracy, adding multi-agent complexity yields diminishing or negative returns (β = -0.408). The coordination tax eats the capability gain.
The Emerging Third Way: Hybrid Architectures
It is rarely a binary choice between "one agent" and "many agents." In 2025, the most successful engineering teams are deploying Hybrid Systems that use Dynamic Routing (or Request Cascading).
In this model, a lightweight "Router" assesses the complexity of the incoming query.
Simple Query: Routed to a fast, cheap Single Agent (or even a standard LLM call).
Complex Query: Routed to a Multi-Agent swarm for deep research.
Recent studies show that request cascading between MAS and SAS can improve accuracy by 1.1% to 12% while reducing overall token costs by 20% to 88%, depending on your routing strategy and task mix. This ensures you only pay the "Coordination Tax" when the problem is hard enough to justify it.
The Trade-off: Hybrid routing isn't free. The routing decision itself adds 100-300ms of latency and requires maintaining a classifier LLM. Routing accuracy typically starts lower and reaches 85-95% after tuning, so plan for an initial calibration period where your router learns your traffic patterns.
How to Implement MAS Safely (If You Must)
If you have validated that you meet a Fission Threshold, do not build a chaotic swarm of chatbots. Build a Deterministic System.
1. Ban Free-Text Communication
Agents should not "chat" with each other in natural language. That leads to drift.
Solution: Use Strict Contracts. Agent A sends a JSON object to Agent B. It is a function call, not a conversation.
2. Implement Circuit Breakers
Never let agents run without guardrails.
Rule: Set cost caps appropriate to task complexity (e.g., $0.10 for simple queries, $1-10 for complex research). Enforce a hard stop at 10 iterations per agent to prevent infinite loops.
3. Centralized State Management
Avoid peer-to-peer negotiation where no one knows the global state.
Solution: Use graph-based orchestration (like LangGraph) where a central "Blackboard" state tracks the workflow. This allows you to "time-travel" debug and see exactly where the state was corrupted.
4. Observability: The Non-Negotiable Foundation
You cannot fix what you cannot see. Production AI systems require:
Distributed Tracing: To visualize workflows across multiple agents.
Token-Level Cost Tracking: To identify exactly which agent is draining your budget.
Replay Capabilities: To reproduce failures exactly as they happened.
Automated Evaluations: To catch regressions before they hit production.
Platforms like PromptMetrics provide deep cost visibility and control, while tools like LangSmith offer extensive tracing for LangChain ecosystems. Choose a tool that fits your stack, but ensure it gives you per-agent cost attribution.
Verdict: Who Should Choose What?
Choose a Single-Agent Architecture if:
You are building a Customer Support Bot, a Coding Assistant, or a Data Analysis tool.
Your task requires deep, sequential reasoning (A implies B implies C).
You need to keep costs low and debugging simple.
Verdict: This covers most common enterprise use cases: customer support, coding assistance, data analysis, and document generation.
Choose a Multi-Agent Architecture if:
You are building a massive Research Engine or a Simulation.
You need to enforce strict security boundaries (Air-gapped steps).
You need to execute 50+ independent tasks in under 30 seconds.
Verdict: Essential for scale, but requires a dedicated Platform Engineering team to manage.
Summary
The difference between a successful AI deployment and a failed pilot is often the refusal to over-engineer.
Complexity is a cost, not a feature.
Start with a single agent. Push it to its limits with Chain-of-Thought prompting, RAG, and reasoning models (like o1/o3). Only when that monolith breaks due to genuine constraints, context, security, or time should you introduce the complexity of a multi-agent system.
When you do, treat it like critical infrastructure: observe it, contain it, and measure it.
Next Steps
Are you paying the "Coordination Tax"?
If your AI costs are spiraling or your agents are looping, you might be over-architected.
Action: Review your architecture against the Fission Protocols above. If you cannot justify your multi-agent setup with one of those three criteria, consider testing a single-agent pilot or a Hybrid Router this week.
When to Revisit Your Architecture Decision:
Reasoning models hit context limits: If your single agent starts "forgetting" instructions due to a long context.
Security audits require provable isolation when your CISO demands separate environments for different tasks.
Task volume justifies parallelization: When users complain about latency, and tasks are clearly independent.
Expected payback: Significant reduction in token spend through architectural simplification and selective agent invocation.
Critical path: Audit Architecture → Simplify to Single Agent → Benchmark Accuracy → Only Split if Fission Criteria Met.