
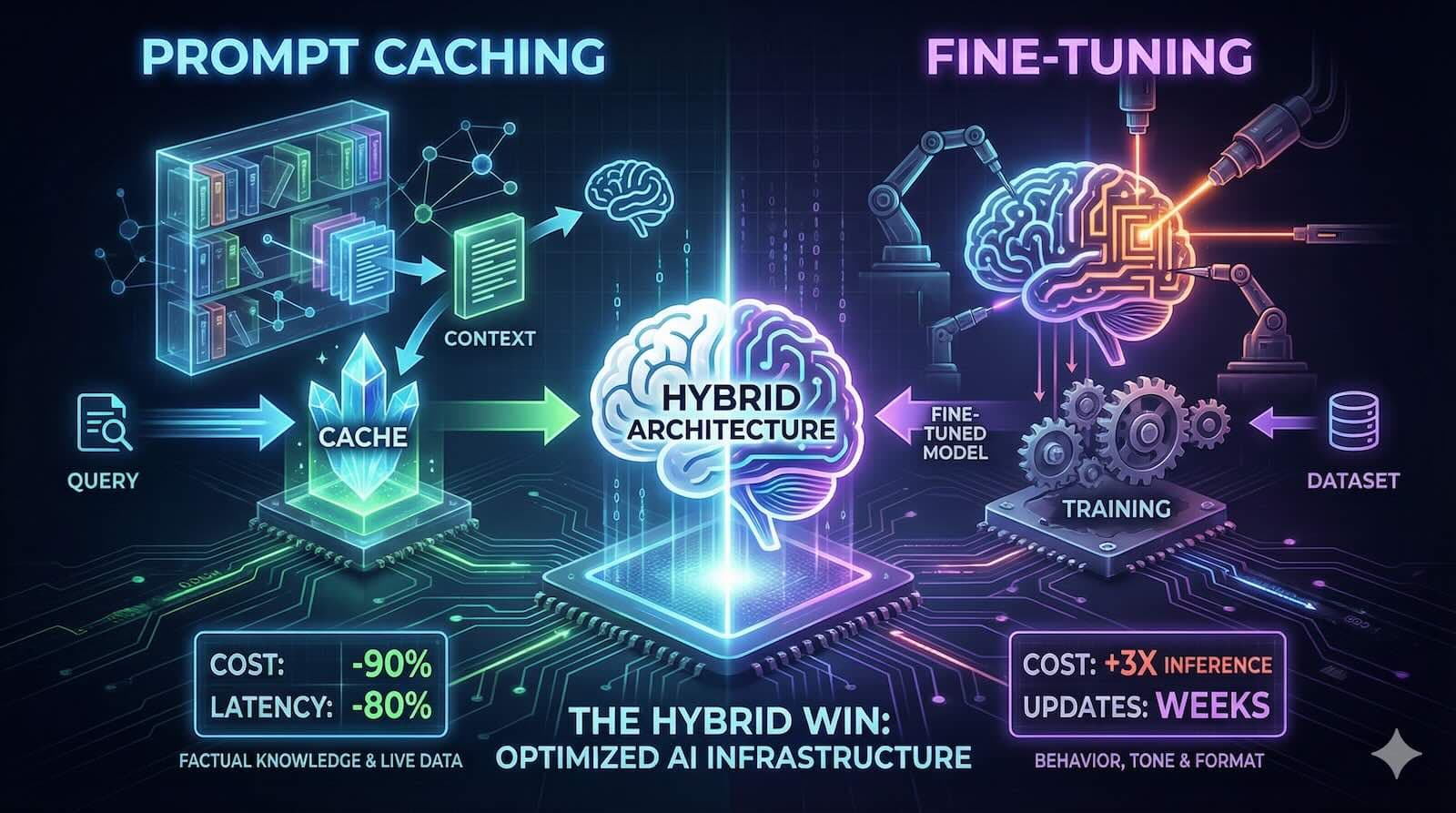
TL;DR: The Executive Summary
The Trap: Teams often try to "teach" models facts (prices, policies) via fine-tuning. This is architecturally wrong. Fine-tuning creates rigid "muscle memory," not a database.
The Rule: Use Prompt Caching for Information (what the model knows). Use Fine-Tuning for Behavior (how the model behaves and formats).
The Economics: Caching reduces input costs by 90% and latency by 80% with zero training overhead. Fine-tuning often increases inference costs by 3x per token.
The Hybrid Win: The best architecture uses fine-tuning for tone/format combined with caching for knowledge injection.
Immediate Action: Audit your fine-tuned models. If you are fine-tuning for facts, migrate to caching to recover ~75% of your compute spend immediately.
Is your LLM bill spiraling while your engineering team spends weeks retraining models to update a product price?
If you are a CTO or VP of Engineering building AI agents, you are likely facing the "Context Trap." You need your model to deeply understand your business—your policies, your codebase, your customer history —but injecting that data is expensive.
For years, the standard solution for factual retrieval has been RAG (Retrieval-Augmented Generation). However, many teams still fall into the trap of believing that fine-tuning is the ultimate step to make a model "learn" their domain data.
This creates architectural rigidity that most teams underestimate.
Research and production data are precise: fine-tuning is structurally misaligned with knowledge injection. With the rise of production-grade Prompt Caching, the economics of AI infrastructure have shifted. Relying on fine-tuning for facts isn't just technically fraught; it can inflate your Total Cost of Ownership (TCO) by 60–80%.
This guide breaks down the technical and economic realities of Prompt Caching vs. Fine-Tuning, corrects common misconceptions, and provides a decision framework for your infrastructure.
The Core Distinction: Information vs. Behavior
To optimize your architecture, we must correct a fundamental category error. You must distinguish between what you want the model to know and how you want it to act.
Think of Fine-Tuning like muscle memory for an athlete. You train reflexes (output formatting, tone, style) so they execute automatically without thinking. But muscle memory doesn't work for facts that change quarterly—you wouldn't "train" an athlete to memorize a price list that updates weekly. You'd give them a reference sheet (Caching) they can glance at instantly.
Informational Context (The "What"): Facts, policies, documentation, schemas, and live data. This changes frequently (e.g., Q3 pricing, new feature specs).
Behavioral Context (The "How"): tone, reasoning style, JSON output strictness, and safety boundaries. This is stable (e.g., "Always answer in valid FHIR JSON," "Be professional").

The Technical Reality:
Fine-tuning modifies model weights through gradient descent. It doesn't "database" facts; it adjusts probability distributions over tokens. When your product manual changes, those probability distributions become outdated. The model has no mechanism to "unlearn" obsolete information without a complete retraining cycle, leading to high risks of hallucinations.
The Rule of Thumb:
Use Prompt Caching (or RAG) to inject information.
Use Fine-Tuning to encode behavior.
Comparison Matrix: At a Glance
Here is how the two approaches stack up for an enterprise processing 10M+ tokens/month.
Feature / Factor | Prompt Caching | Fine-Tuning | The Reality |
Primary Purpose | Injecting Information (Docs, Code, History) | Encoding Behavior (Tone, Format, Style) | Fine-tuning is poor at factual recall (hallucination risk). |
Cost Structure | Pay per query. 50-90% discount on cached tokens. | High Capex (Training) + Higher Opex (Inference often 3x base model). | Fine-tuning adds no input tokens and increases unit costs. |
Latency (TTFT) | Ultra-Low. 80-85% reduction (skips processing prefix). | Standard. No latency benefit over base model. | Caching improves UX significantly. |
Update Velocity | Instant. Update the text file; the following query will use the new data. | Weeks. Requires data prep, training runs, and eval suites. | Caching equals agility; Fine-tuning equals rigidity. |
Data Privacy | Context sent at inference (auditable & ephemeral). | Data "baked" into model weights (hard to unlearn/audit). | Fine-tuning makes PII removal nearly impossible. |

Deep Dive: Prompt Caching
The "Inject and Forget" Engine
Prompt Caching exploits the Key-Value (KV) cache in transformer architectures. Instead of re-computing the attention states for your massive 20,000-token system prompt every time a user asks a question, the API provider stores that computed state.
The Economics (Jan 2026 Pricing):
Let's look at the math for a GPT-5 class model to see the real impact on margins.
Scenario: 5,000 tokens of context × 1M queries/month.
Uncached Cost: 5B tokens × $0.625/M = $3,125
Cached Cost: 5B tokens @ $0.0625/M (90% discount) = $312.50
Net Savings: $2,812.50/month ($33,750/year) just on inputs.
The Performance Win: Latency
Beyond cost, caching delivers 80-85% latency reduction on cached prefixes. Because the model skips the computation for the cached block, Time-to-First-Token (TTFT) drops dramatically.
Uncached TTFT: ~8-12 seconds for large contexts.
Cached TTFT: ~1-2 seconds.
For user-facing applications, this latency improvement often justifies caching even before the cost savings.

The "Gotcha": Cache Invalidation
The Achilles' heel of caching is invalidation. If you change even one token in the prefix, the entire cache for that block is invalidated.
Fix: Structure your prompts strategically. Place stable content (Company Mission) first, moderately stable content (Product Catalog) second, and dynamic content (User Query) last.
Compliance Advantage
For European CTOs dealing with the EU AI Act: Caching creates a clear audit trail. You can prove, "The model generated this answer using Policy Document v3.2." With fine-tuning, the "why" is buried in opaque weight matrices, making explainability difficult.
Deep Dive: Fine-Tuning
The "Muscle Memory" Specialist
Fine-tuning adjusts the neural network's weights to favor specific patterns. While excellent for behavior, it comes with hidden costs.
The Hidden Cost: Iteration
A production-ready fine-tuned model rarely emerges from a single training run. You are not just paying for one run; you are paying for an R&D cycle.
Training Costs: Upfront spend of $25–$100 per million training tokens.
Iteration Reality: Typical projects require 5-10 runs to tune hyperparameters and fix quality issues.
Real Cost: A 5M-token dataset might cost $1,250 in training compute and 2-6 weeks of engineering time. While your team iterates, they could have shipped the caching solution in 48 hours.
The Silent Killer: Inference Premium
Fine-tuning is often sold as a cost-saver ("shorter prompts!"), But the math rarely holds up because the unit economics change. Fine-tuned models usually cost 3x as much per token as base models (e.g., $3.00/M vs $1.00/M). You pay a premium on every interaction, forever.
Evaluation Debt & Catastrophic Forgetting
Fine-tuning carries the risk of the model over-indexing on your data and losing general intelligence.
Real World Example: A fintech startup fine-tuned GPT-4 on 10,000 mortgage applications. The model became excellent at extracting loan terms—but started failing basic arithmetic ("What's 15% of $500,000?"). Why? The dataset contained no math examples, so the model's weights drifted away from general capabilities.
Implementation Guide: Provider Specifics
Not all caching is created equal. Here is how the major players handle it:
OpenAI (GPT-5): Automatic. No code changes required. The API detects matching prefixes and automatically applies the discount. Tip: Keep your system prompt static at the start.
Anthropic (Claude Sonnet 4): Manual. Requires explicit cache control via API headers. You must set "breakpoints" in your prompt and manage a Time-To-Live (TTL) of usually 5 minutes to 1 hour.
DeepSeek: Disk-Based. DeepSeek has introduced aggressive pricing with disk-based caching. Note: Verify current pricing on their docs, as this changes rapidly, but reports indicate up to 90% discounts on cache hits.
Use Case Scenarios: Which Architecture Fits?
Scenario A: The "Policy-Aware" Customer Support Bot
Situation: A chatbot answering questions based on SaaS documentation. Docs update weekly.
The Approach: Prompt Caching (mostly).
Logic:
If docs < 128k tokens: Cache the entire documentation set. It is cheaper and faster.
If docs > 200k tokens: Use RAG (Retrieval-Augmented Generation). Caching is not a replacement for searching over millions of documents.
Result: Instant updates when docs change, 90% cheaper inputs, and full traceability.
Scenario B: The Clinical Data Extractor
Situation: Parsing messy doctors' notes into strictly formatted FHIR-compliant JSON. Standards are stable.
The Approach: Fine-Tuning.
Why: You need the model to adhere to a strict syntax, not learn new facts. Research shows fine-tuning can improve complex formatting accuracy from ~5% (base model) to 99%+, justifying the higher inference cost.
Scenario C: The Enterprise Copilot (The Hybrid)
Situation: A massive internal banking tool.
The Approach: Hybrid (Fine-Tuning + Caching).
Strategy: Fine-tune the base model to enforce a formal banking tone and legacy XML formats (Behavior). Then, use Prompt Caching to inject daily interest rates and compliance PDFs (Information) into that fine-tuned model.
Hybrid TCO Example (1M queries/month)
Fine-tuning cost: $500 one-time (setup & training).
Inference (Fine-tuned): $3.00/M × 6B tokens = $18,000/month.
Cached Context (10k tokens): 90% discount applied to the fine-tuned model inputs = $1,875 (instead of $18,750).
Net Result: You get the 99% formatting reliability of fine-tuning, but Caching subsidies the cost, keeping the total bill manageable (~$20k vs ~$37k uncached).
Measuring Success: The Metrics That Matter
To prove the value of this architectural shift to your CFO, track these metrics in your observability platform:
Cache Hit Rate:
Customer Support (Fixed Docs): Target 85-95%.
Code Copilot (Repo Context): Target 70-85%.
Multi-tenant SaaS: Target 60-75% (lower due to tenant-specific data).
Cache Invalidation Frequency: Spikes here mean you are editing the stable parts of your prompt too often.
Cost Per Query: Should drop roughly 50-60% immediately after implementation.
Common Failure Modes (And How to Avoid Them)
Dynamic Content in Cached Prefix: Including timestamps, user IDs, or session data before the cache breakpoint. This kills your hit rate (<10%). Fix: Move all dynamic data to the end of the prompt.
Over-Caching with Short TTL: Caching content that changes every 10 minutes with a 5-minute TTL. Fix: Don't cache rapidly changing data; use standard RAG.
Fine-Tuning Without Evals: Training a model without a regression test suite. Fix: Build a 500+ example eval dataset before you train.
Migration Playbook
If you have already invested in fine-tuning, here is how to pivot without scrapping your work:
Day 1-2: Audit. List all fine-tuned models. Classify them: Information-heavy or Behavior-heavy?
Day 3-4: Implement Caching. For info-heavy models, restructure prompts (static first, dynamic last). Enable provider caching (OpenAI auto / Anthropic manual).
Day 5: Measure. Check Cache Hit Rate (aim for >70% initially). Run your eval suite to ensure the quality matches that of the old fine-tuned model.
Week 2: Scale. Roll out to 100% traffic and deprecate the expensive, information-heavy fine-tuned models.
Why PromptMetrics Built This Guide
We built this guide because we saw European AI teams flying blind. They couldn't see which prompts had high cache-miss rates (silent cost leaks) or whether their fine-tuning actually improved accuracy compared to base models.
Our POV: Observability drives optimization. You can't fix what you can't measure. We wrote this because we've analyzed millions of cached prompt requests across 50+ production systems and seen the same patterns: caching wins on cost, fine-tuning wins on behavior.
Summary
Fine-tuning for knowledge creates unnecessary cost and architectural rigidity. In 2026, the winning architecture is a Hybrid Fleet: using huge context windows and prompt caching to handle your dynamic data, while reserving fine-tuning for niche, high-value behavioral tasks.
Ready to calculate the impact?
We believe in transparency. Our PromptMetrics ROI Calculator uses the exact input/output ratios of your workload to compare the TCO of Caching vs. Fine-Tuning.