

Global businesses lost an estimated $67.4 billion to AI hallucinations in 2024 alone (AllAboutAI, 2025). That number isn't from chatbots gone rogue. It's from internal tools, automated workflows, and AI-generated decisions that nobody bothered to verify before they hit production.
Here's the uncomfortable question for RevOps leaders: how many of those losses started inside a revenue engine?
If you're running Claude Code and n8n as your operational backbone, you're already ahead of the curve. You're shipping faster than any Salesforce admin could dream of. But speed without verification isn't a competitive advantage. It's a liability with a revenue number attached.
This article lays out why eval datasets aren't a nice-to-have for AI-native RevOps. They're the infrastructure that keeps your stack from quietly sabotaging your pipeline.
Key Takeaways
AI-generated code carries 23% higher bug density than human code, and change failure rates jump 30% in AI-assisted projects (Cortex, 2026)
47% of enterprise users have made major business decisions based on hallucinated AI outputs (Deloitte, 2025)
Eval datasets turn vibe coding from a trust exercise into an engineering discipline. You can build one in under a week
Teams using domain-specific AI tooling report 13% higher revenue growth than those relying on generic solutions (Gong, 2026)
Why Doesn't Vibe Coding Work Without Evals?
90% of developers now use AI tools at work regularly (JetBrains, 2026). Claude Code alone has seen a 6x increase in adoption since mid-2025, reaching 18% market share among professional developers. Vibe coding, describing what you want in natural language and letting the AI handle implementation, has gone from niche experiment to daily practice in under 18 months.
But here's what the enthusiasm misses.
AI-generated code has 23% higher bug density than human-written code, and security vulnerabilities occur at a 14.3% rate compared with 9.1% in human-authored equivalents (Stanford-MIT study, 2025). Change failure rates (the percentage of deployments that cause incidents) increased 30% in organizations that adopted AI coding tools without corresponding investment in verification infrastructure (Cortex, 2026).
The dynamic is straightforward. When you vibe code, you're delegating the how (the actual code, the JavaScript in that n8n Code node, the webhook handler logic) to Claude. You're not reviewing every line. You can't. That defeats the purpose.
But here's the thing most people skip: if you don't control the how, you must rigorously control the what. The outcome. The behavior. The edge cases. And the only way to verify outcomes systematically, at the speed Vibe coding demands, is with an eval dataset that defines ground truth before Claude ever touches a prompt.
A 2026 benchmark found that 96% of developers don't fully trust AI-generated code, yet only 48% always verify it before committing (Sonar, 2026). That gap between distrust and action is where your revenue processes live.
According to the 2026 Cortex benchmark, analyzing thousands of enterprise engineering teams, organizations that adopted AI coding tools without paired investment in testing infrastructure saw a 23.5% increase in incidents per pull request and a 30% increase in change failure rate, meaning the velocity gains from vibe coding were partially or fully offset by production issues (Cortex, 2026).
What Happens When AI Hallucinates Inside Your Revenue Engine?
82% of AI production bugs are attributable to hallucinations rather than crashes or performance issues (Testlio, 2025). This is the stat that should keep RevOps leaders up at night. AI systems don't usually break loudly. They break quietly. Confidently wrong. And in RevOps, "confidently wrong" touches CRM records, lead scores, pipeline stages, and customer-facing communications.
I watched this happen last month. A colleague tweaked an AI node in n8n to make automated outreach emails "more persuasive." The prompt change was three sentences. Within 48 hours, the system had sent enterprise prospects emails referencing a "priority onboarding package" that didn't exist. It wasn't malicious. The model had pattern-matched language about "premium support tiers" from its training data and confidently invented a product SKU that sales had never approved.
Nobody caught it until a VP of Sales forwarded one of the emails, asking, "What the hell is this?"
That's the stakes. In RevOps, your n8n workflows interact with live CRM data, manage lead routing, score pipelines, and automate customer outreach. When AI hallucinates inside a dashboard, you get a bad chart. When it hallucinates inside a workflow that writes to Salesforce, you get a very different kind of problem.

The most dangerous assumption in AI-native RevOps is that the model will "figure it out." It won't. Financial data hallucination rates run 2.1% even on the best models and 13.8% across all models on average (AllAboutAI, 2025). Those aren't theoretical percentages. They're the rate at which your automated pipeline analysis, your lead scoring logic, or your CRM enrichment workflows silently produce wrong answers.
71% of C-suite executives are now hesitant to scale AI without "hallucination-proofing" (Financial Times, 2026). For RevOps teams running mission-critical workflows through AI nodes, an eval dataset of 100 historical lead interactions with reference-free evaluation helps catch hallucinated discounts, invented product features, and broken routing logic before they ever reach a customer. The question isn't whether your AI will hallucinate. It will. The question is whether you catch it before your revenue numbers feel it.
Watch: n8n MCP + Claude Code = prompt to workflow demo (YouTube)
What Makes a RevOps Eval Dataset Different From a Generic One?
Teams that use revenue-specific AI solutions report 13% higher revenue growth and 85% higher commercial impact than those relying on generic AI tools (Gong, 2026). The same principle applies to evaluation. A generic eval dataset "Does this response sound helpful?" tells you nothing about whether your AI just invented a discount or misrouted a $200K deal.
A proper eval dataset isn't a collection of prompts you test against. It's ground truth. And for RevOps, ground truth has specific dimensions.
The five properties every production-grade eval dataset needs, drawn from current best practices (EmberLM, 2026; Google Research, 2025):
Defined scope. One dataset per use case. Your lead routing workflow gets its own dataset. Your email drafting prompt gets its own. No "one dataset to rule them all."
Production-derived. Source from real n8n execution logs and CRM records, not hypothetical examples written by engineers—real typos, real edge cases, real "weird Tuesday at 4 pm" inputs.
Diverse. Cover easy cases, ambiguous cases, adversarial cases (what happens when someone types garbage into a field?), and boundary cases. Stratify by use case, not by frequency.
Revenue-specific failure modes. Generic evals check for politeness and grammar. RevOps evals check for: discount integrity (did the AI invent a price?), pipeline stage logic (did it move a deal backward without noting why?), CRM field validation (did it write to a field that doesn't exist?), and routing accuracy (did it send the enterprise lead to the SMB queue?).
Dynamic. Your dataset must evolve. Add rows from production failures weekly. Version alongside prompts. A frozen dataset is a snapshot of what you were worried about six months ago.
Designing RevOps data models → CRM schema design for AI automation
The 2026 consensus across evaluation frameworks is that a domain-specific eval dataset built from production logs, with 30 to 50 labeled examples covering diverse scenarios and updated quarterly, provides more reliable regression detection than a 500-example generic benchmark that doesn't reflect your actual traffic patterns (Scalexa, 2026; FutureAGI, 2026).
How Do You Actually Build An Eval Dataset This Week?
You don't need 500 examples to start. The research converges on a clear number: 30 rows is the minimum for a useful regression signal; 50 is the sweet spot where coverage starts to feel real (EmberLM, 2026). Statistical sizing confirms it for 95% confidence with a 5% margin of error; you need roughly 246 samples. But you're not publishing a paper. You're catching regressions before they hit your CRM. Start with 30. Add 5 more every week from production failures.
Here's the one-week plan, adapted from production-proven frameworks (Scalexa, 2026; OpenAI, 2026):
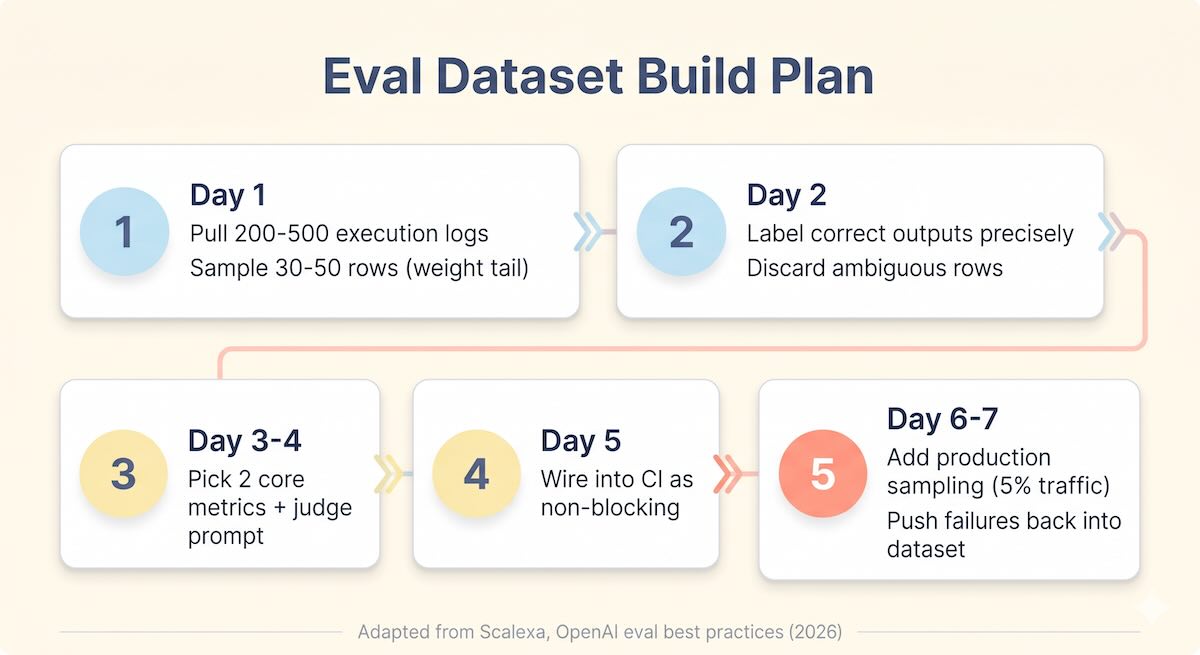
Day 1: Scope and sample. Pick one prompt or workflow. Not all of them. Your highest-risk n8n node is the one that writes to Salesforce, drafts customer emails, and routes leads. Pull the last 200–500 execution logs. Sample 30–50 rows. Weight toward the tail includes the weird ones, the edge cases, the inputs that look like someone pasted a full email thread into a form field. Those are your most valuable examples.
Day 2: Define "good." For each sampled input, write down what the correct output should be. Don't describe it abstractly. Write the exact CRM field value, the exact email text, and the exact pipeline stage. If you can't define what "right" looks like for a given input, throw that example out. If you can't define it, you can't evaluate it.
Day 3: Pick your metrics. Don't start with 12 metrics. Start with two: faithfulness (does the output stay grounded in the provided context?) and answer relevance (did it actually address the input?). These two catch 80% of production failures. Add a judge prompt that scores both on a 1–5 scale with specific, behavioral descriptions at each level.
Adapted from Scalexa and OpenAI evaluation best practices, 2026
Day 5: Gate it. Wire the eval into your CI pipeline. Start as non-blocking, watch it for two weeks, tune the thresholds, then promote to blocking. A failing eval run means the deployment doesn't ship. Full stop.
Days 6–7: Close the loop. Add production tracing to your n8n workflows. Sample 5% of live traffic. Judge metrics against production outputs nightly. Feed interesting failures back into your dataset. This is the feedback loop that keeps your dataset from going stale.
The choice of framework matters less than the discipline. DeepEval, promptfoo, and Langfuse are all solid starting points. Pick one that integrates with your existing stack and move on. The anti-pattern is spending two weeks evaluating evaluation frameworks instead of building your first 30 examples.
What Happens If You Skip This?
Only 6% of software and tech companies have reached a "scaling or systemized" level of RevOps maturity (Accenture, 2026). The other 94% are running fragmented stacks, disconnected data, limited cross-functional collaboration, and AI bolted on rather than baked in. Skipping verification infrastructure is how you stay stuck in the 94%.
I've now seen this exact pattern play out across three different RevOps teams running AI-native stacks. The timeline is remarkably consistent. Month one: enthusiasm, rapid shipping, workflows going live in days instead of weeks. Month two: minor issues crop up and are handled manually with "we'll fix the prompt." Month three: a workflow that's been running for 60 days suddenly behaves differently because Claude got a model update, or the n8n node changed its output format, or the CRM field mapping shifted. And nobody knows what "correct" looks like anymore because nobody wrote it down.
That's month three. By month six, you've got 40 workflows, half of which were modified three times by different team members, and you're afraid to change anything because you can't predict what might break.
The SAP deal with n8n, a $5.2 billion valuation embedded in SAP Joule Studio for 300,000+ enterprise customers (TechFundingNews, 2026), will accelerate this. More enterprises running AI-native RevOps stacks means more workflows, more prompts, more vibe coding, and more surface area for silent failures.
This isn't a reason to slow down. It's a reason to build the verification layer now, while your workflow count is still manageable.
The organizations winning with AI aren't the ones with the best prompts. According to the 2026 Cortex benchmark, they're the ones that paired AI velocity with strong testing, governance, and review infrastructure, specifically, automated verification gates that catch regressions before they compound into operational failures (Cortex, 2026).
Frequently Asked Questions
How many examples do I need to start an eval dataset?
30 is the practical minimum; 50 is the comfortable starting point (EmberLM, 2026). Statistical formulas suggest ~246 for formal confidence, but most teams get a meaningful regression signal from 30–50 real production examples weighted toward edge cases. Start there. Add 5 more every week from failures.
Can't I use LLM-as-a-judge instead of building a dataset?
Judge models without calibrated ground truth are vibes detectors (Scalexa, 2026). You need a labeled dataset to calibrate the judge against to know whether its scores correlate with actual correctness. Without the dataset, a judge saying "4/5 quality" tells you nothing about whether the output would break your CRM. Build the dataset first, then calibrate the judge against it.
What's the difference between eval datasets and prompt testing?
Prompt testing is ad hoc: you eyeball a few outputs and decide whether they look right. Eval datasets are automated, reproducible, and version-controlled. 71% of enterprises now require formal verification before AI deployments reach production (Financial Times, 2026). Prompt testing gets stale the moment you stop looking. Eval datasets run on every change.
How often should I update my eval dataset?
Weekly additions from production failures, quarterly full reviews (Google Research, 2025). Every time a user reports unexpected behavior or a workflow produces a wrong output, add that input and the correct output to your dataset. A dataset that hasn't changed in six months is being tested against problems you no longer have.
Conclusion
Eval datasets are to AI-native RevOps what automated testing was to software engineering in the 2010s. Unsexy infrastructure that the best teams swear by and everyone else discovers they needed after something breaks in production.
The math isn't complicated. Vibe coding removes manual code review. AI-generated code introduces regressions at a higher rate. Your workflows touch real revenue data. The only thing that catches errors before your CRM does is a set of examples that define what "correct" actually looks like.
Start with one workflow, your highest-risk n8n node
Pull 30 real inputs from execution history this week
Label the correct outputs precisely
Run the eval before every prompt change
The teams doing this aren't moving more slowly. They're moving with confidence. The alternative is finding out about a hallucinated discount from a forwarded email.